
Dando continuidade a nossa série de artigos voltados ao Kafka Stream (veja aqui a introdução a nossa série de artigos), vamos agora montar nosso projeto base, ainda sem muita lógica de negócio mas precisamos ter o esqueleto rodando para começar a construir nossa aplicação de saldo. O que teremos ao final deste post ?
- Docker Compose com Kafka + Zookeeper + AKHQ + Aplicação Kafka Streams.
- Makefile para iniciar e parar tudo.
- Projeto Kafka Streams usando Maven, consumindo de um tópico de input e gravando em um tópico de output.
Todo o código pode ser encontrado neste repositório do Github: https://github.com/kafkabrasil/kafka-streams-aplicacao-saldo.
Vamos começar analisando nosso Docker Compose, a ideia não é ensinar Docker então vamos focar apenas nos pontos mais importantes e relevantes deste arquivo docker-compose.yaml.
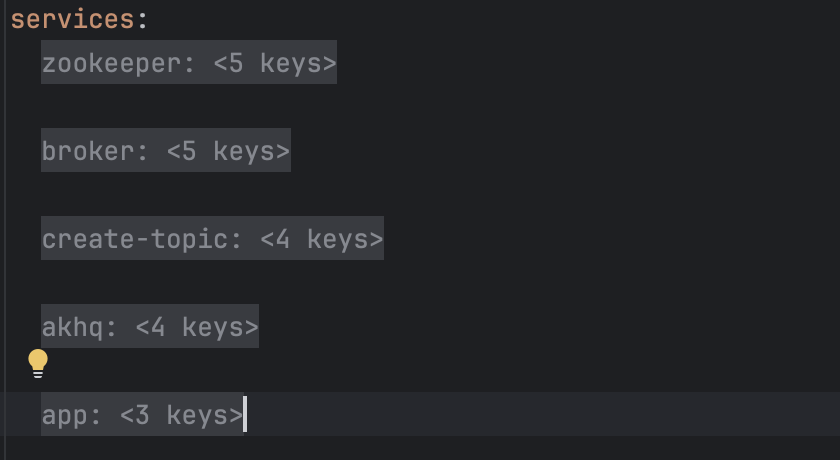
Esses são os nossos serviços, vamos listar cada um deles:
- zookeeper + broker: Ambos juntos são necessários para que o Cluster de Kafka esteja funcional. Nas novas versões poderíamos remover o Zookeeper e usar o Kraft, mas por enquanto vamos mantê-lo.
- create-topic: Criamos um script em bash para criar o nosso tópico de input assim que o broker subir, assim a aplicação streams não irá dar erro.
- akhq: Interface gráfica responsável por gerenciar o cluster de kafka.
- app: Nossa App que irá consumir de um tópico e produzir em outro, fazendo uma transformação bem simples.
Vamos dar um zoom na nossa App e entender alguns detalhes importantes:
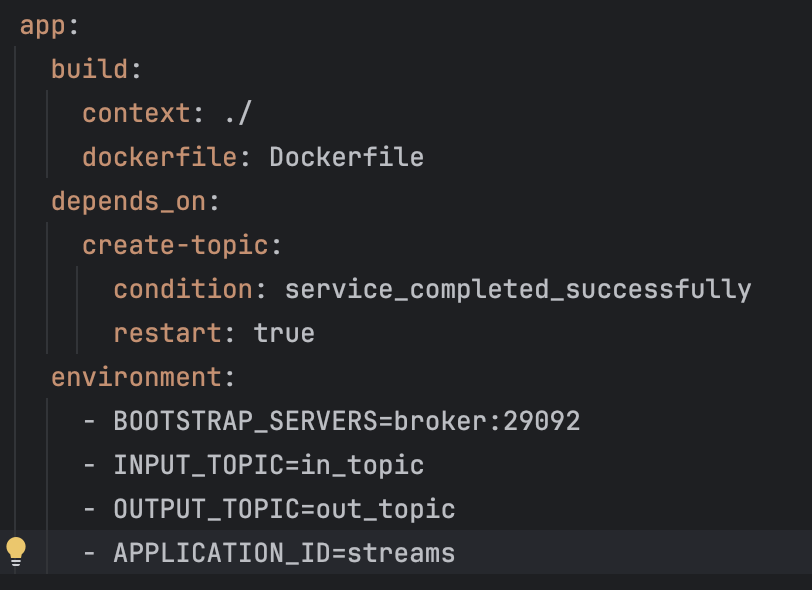
Nossa App só pode subir depois que o tópico estiver criado, por isso criamos uma dependência com o create-topic. Além disso, todas as informações necessárias para nossa App rodar corretamente são expostas em variáveis de ambiente, assim podemos mudar qualquer config sem precisar fazer o build novamente.
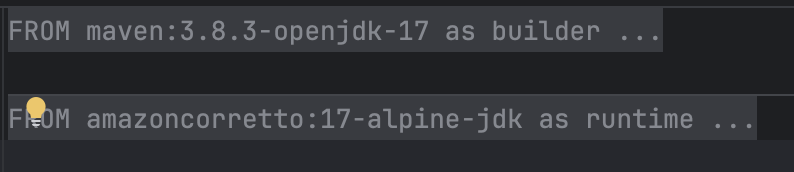
Nosso Dockerfile segue um padrão de multi-stage , assim garantimos otimização do artefato final gerado. Separamos em stage builder e runtime, onde o runtime é o que realmente vai ser entregue.
Usamos Makefile para facilitar a manipulação do nosso projeto. Se você digitar make na raiz do projeto poderá ver a lista de comandos disponíveis. Lembrando que o Make já vem por padrão no MacOS e no Linux, então se você está usando Windows terá que instalar algum emulador.
Vamos agora entrar no código. Temos apenas uma classe, ProcessadorSaldo, nela temos 2 métodos: configurarStreams() e criarStreams().
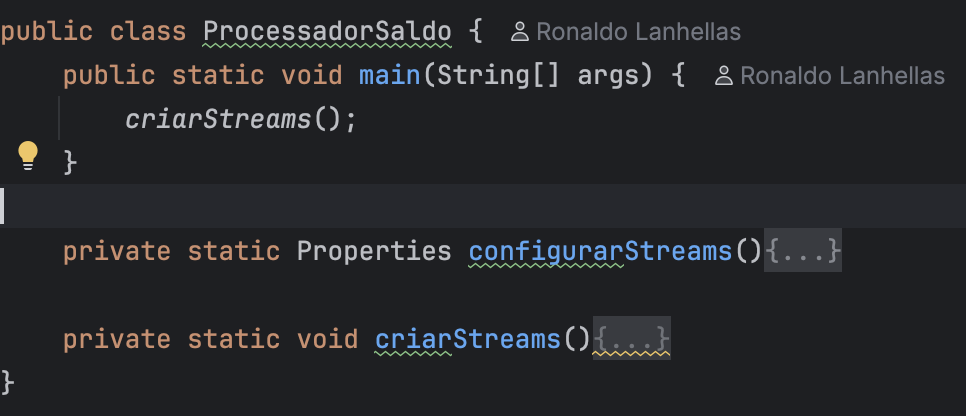
O método configurarStreams() é responsável por instanciar um objeto Properties com várias configurações que a lib do kafka streams precisa para entender qual o endereço do broker de kafka, nome de tópicos, serialização e deserialização de mensagens, nome do consumer group e etc.
Onde realmente tudo acontece é dentro do método criarStreams(), vou separar em partes:

Primeiro vamos criar o KStream, que é a interface responsável por receber o stream de dados, até o momento não estamos consumindo nada, apenas configurando o tópico de entrada. Note que estamos usando generics para dizer que o valor é do tipo string e a chave também é do tipo string.

Usamos o método mapValues para pegar cada item do stream e realizar transformações, nesse caso estamos pegando o valor e adicionando a palavra “- Processed” apenas para saber que realmente está funcionando.

Escrevemos tudo isso em uma saída, nosso tópico de saída.
Isso que montamos acima é chamado de Topologia. Dizemos como seria feita a entrada, a transformação e a saída.

É por isso que ao chamar o método build() uma topologia é retornada.

Para finalizar, criamos um objeto KafkaStreams que é o real responsável por executar toda a topologia acima definida. O método start() irá iniciar o consumo das mensagens e passar todas elas pela nosso topologia definida acima.
Lembre que este ainda não é o projeto final, apenas gostaria que você entendesse como funciona o Hello World com Kafka Streams, nos próximos posts começaremos a alterar nosso código para implementar nossa lógica de tratamento de saldo e extrato da nossa aplicação.
Abaixo preparei um video bem curto mostrando tudo isso funcionando junto:


Comments
Pingback: Kafka Streams – Introdução e Caso de Uso - Kafka Brasil